MSPT
Efficient Large-Scale Physical Modeling via Parallelized Multi-Scale Attention
Pedro M. P. Curvo · Jan-Willem van de Meent · Maksim Zhdanov
University of Amsterdam
 arXiv
arXiv GitHub
GitHub HF Checkpoints
HF CheckpointsAbstract
Scaling neural solvers without losing global structure
A key scalability challenge in neural solvers for industrial-scale physics simulations is efficiently capturing both fine-grained local interactions and long-range global dependencies across millions of spatial elements. MSPT combines local point attention within patches with global attention to pooled patch-level representations. To partition irregular geometries into spatially coherent patches, MSPT uses ball trees. This dual-scale design enables scaling to millions of points on a single GPU while maintaining high accuracy on PDE and CFD benchmarks.
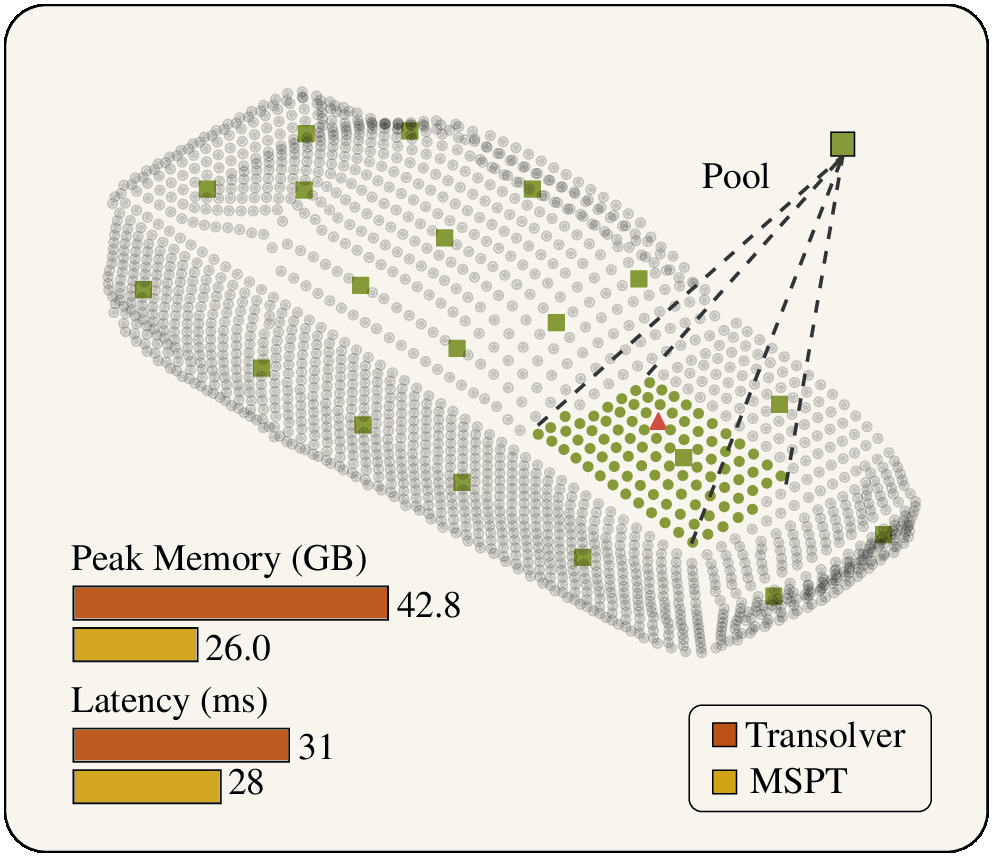
Contributions
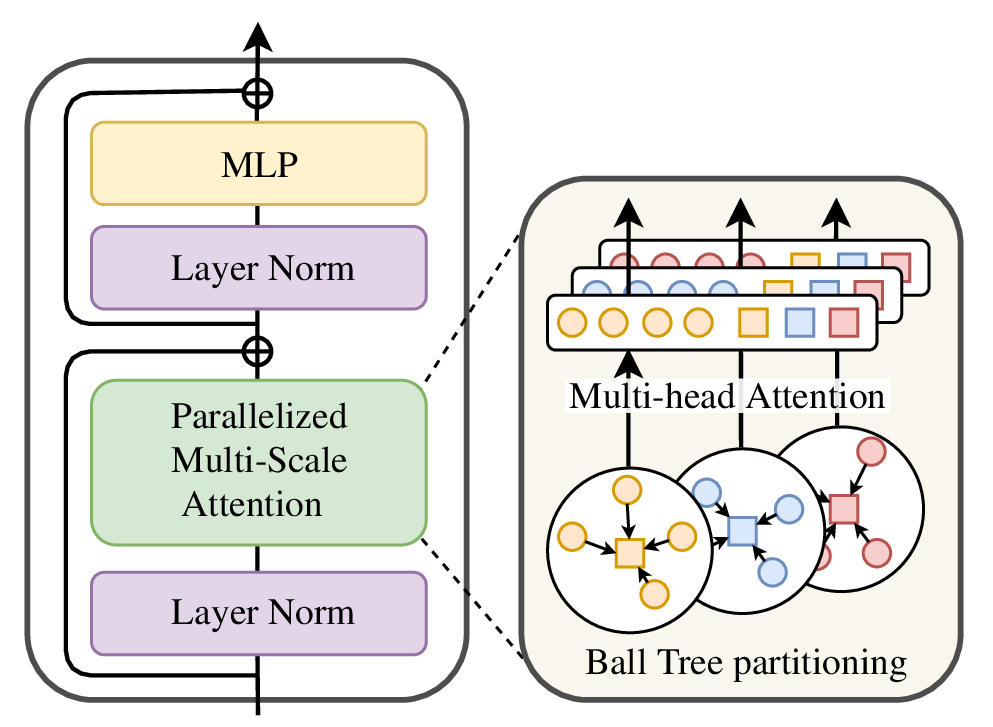
Introduces Parallelized Multi-Scale Attention (PMSA), combining local patch attention with global cross-patch communication in a single attention pattern.
Builds MSPT as a multi-block transformer for arbitrary geometries and changing resolutions using ball-tree partitioning and supernode pooling.
Shows strong performance on standard PDE tasks and large-scale aerodynamic datasets while keeping memory and runtime scaling practical.
Method
Patch locally, communicate globally
Given point features, MSPT partitions the domain into K patches of size L. Each patch is pooled into Q supernodes. Attention is then computed on augmented tokens that include both local patch tokens and global pooled tokens, enabling simultaneous local detail modeling and long-range communication.
- Partition N spatial elements into K coherent patches using ball trees.
- Pool each patch into Q supernodes to expose long-range structure without paying full global-attention cost.
- Run attention over local tokens plus pooled global tokens, yielding complexity O(NL + N^2Q/L).
Complexity
O(NL + N^2Q/L)
With practical settings where KQ << N, the architecture preserves local fidelity while keeping global context affordable.
Main results
Benchmark performance across PDE and aerodynamic tasks
PDE Standard Bench
Relative L2 error where lower is better
| Model | Elasticity | Plasticity | Airfoil | Pipe | Navier-Stokes | Darcy | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FNO | / | / | / | / | 15.56 | 1.08 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
... show 14 more baselines
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MSPT (Ours) | 0.48 | 0.10 | 0.51 | 0.31 | 6.32 | 0.63 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Relative Promotion | -41% | 17% | 4% | 6% | 30% | -10% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ShapeNet-Car
Relative L2 error where lower is better
| Model | Volume | Surf | CD | rhoD | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simple MLP | 5.12 | 13.04 | 3.07 | 94.96 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
... show 11 more baselines
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MSPT (Ours) | 1.89 | 7.41 | 0.98 | 99.41 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Relative Promotion | +8.7% | +0.5% | +4.9% | +0.06% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AB-UPT | 1.16 | 4.81 | N/A | N/A | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AB-UPT (repr.) | 2.51 | 7.67 | 2.20 | 97.48 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
AhmedML
Relative L2 error where lower is better
| Model | Volume | Surf | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet | 5.44 | 8.02 | |||||||||||||||||||||
... show 7 more baselines
| |||||||||||||||||||||||
| MSPT (Ours) | 2.04 | 3.22 | |||||||||||||||||||||
| Relative Promotion | +0.49% | +6.67% | |||||||||||||||||||||
| AB-UPT | 1.90 | 3.01 | |||||||||||||||||||||
| AB-UPT (repr.) | 2.39 | 4.33 | |||||||||||||||||||||
Ablation and efficiency
Where the gains come from
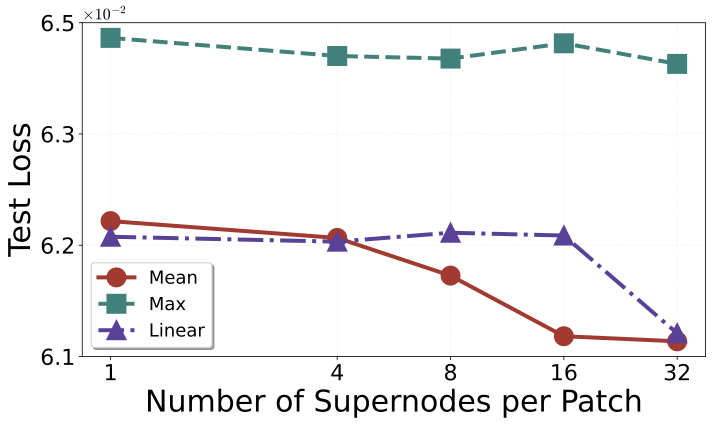
Q) ablation on ShapeNet-Car.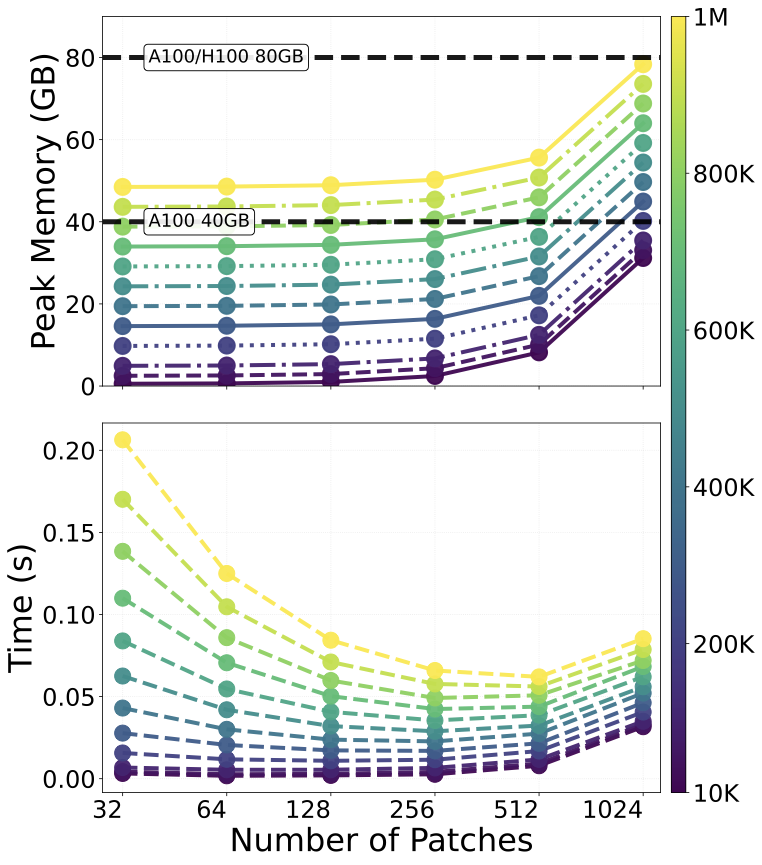
Quick Start
git clone --recurse-submodules https://github.com/pedrocurvo/mspt.git
cd mspt/Neural-Solver-Library-MSPT
pip install -r requirements.txt
bash ./scripts/StandardBench/plasticity/MSPT.shCitation
@InProceedings{curvo2026mspt,
title={MSPT: Efficient Large-Scale Physical Modeling via Parallelized Multi-Scale Attention},
author={Pedro M. P. Curvo and Jan-Willem van de Meent and Maksim Zhdanov},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026},
url={https://arxiv.org/abs/2512.01738},
}Also available at